How we automated technical implementation
Most startups scale onboarding by hiring forward-deployed engineers. We built Anvil to do most of it in software, before reaching for people.
At Antimetal, one of the things we care about most is how quickly we can get a new customer set up and using the product. The goal we hold ourselves to is taking someone from signing up to fully live in a matter of hours.
That turns out to be a hard thing to promise, because no two customers look the same. Each one arrives with its own setup, its own integrations, and its own security requirements, and all of it has to be understood and configured correctly before the product can do anything useful for them.
The usual way companies deal with this is to hire their way through it, building out teams of forward-deployed engineers (FDEs) who sit between the product and the customer and do the manual work of making the two fit together.
However, we've found that many earlier stage startups that hire FDEs underestimate how much of the work of implementation can be automated, and how much it matters as a technology principle to automate what you can.
We believe that onboarding a customer onto our product is at its core a technology problem, and that a product company should be able to solve it with software rather than headcount.
Introducing Anvil
Anvil is an internal application that our team built to make it painless for us to onboard our customers while guaranteeing a high quality control bar across all new users. It automates most of the technical setup that our engineers used to do by hand and remains the source-of-truth for every new onboarding.
It's tempting to call Anvil a pipeline or even a CRM. It does carry a customer through an ordered set of steps, from early discovery to going live. However, Anvil is not simply a system of record, it's an autonomous implementation tool that does the work itself.
Anvil has direct, authenticated access to our production systems and third-party integrations, so it can execute most onboarding steps end to end and only introduces human-in-the-loop when strictly necessary.
If a step needs to determine preferential information about what feature-set a customer is looking for, Anvil interprets our customer call logs and makes its own conclusions. If an integration needs to be connected, Anvil handles the setup itself. If Anvil needs to confirm something is working, it runs health checks and test payloads on its own using our internal and 3rd-party integration MCPs, then reports its results to us.
Humans are continuously looped into verification and judgment steps, but otherwise this implementation process largely runs autonomously in the background as we build new features for our customers.
Anvil comes with many powerful properties:
- Full data access: It integrates with every production data source and 3rd party integration at Antimetal.
- Single source-of-truth: it centralizes all of our post-sale customer onboarding information.
- Verification and evaluation suites: it has a full, programmable range of verification and eval suites to iterate on the intelligence we offer each customer.
- Productivity suite features: it boasts a complete RBAC model, audit logging, notification management, project tracking, and an analytics control plane.
- Continuously evolving with product: its internal data architecture is designed for incredibly fast and easy evolution. If a new step is added to onboarding, the step can be conditionally applied to just one customer without affecting other customer onboardings.
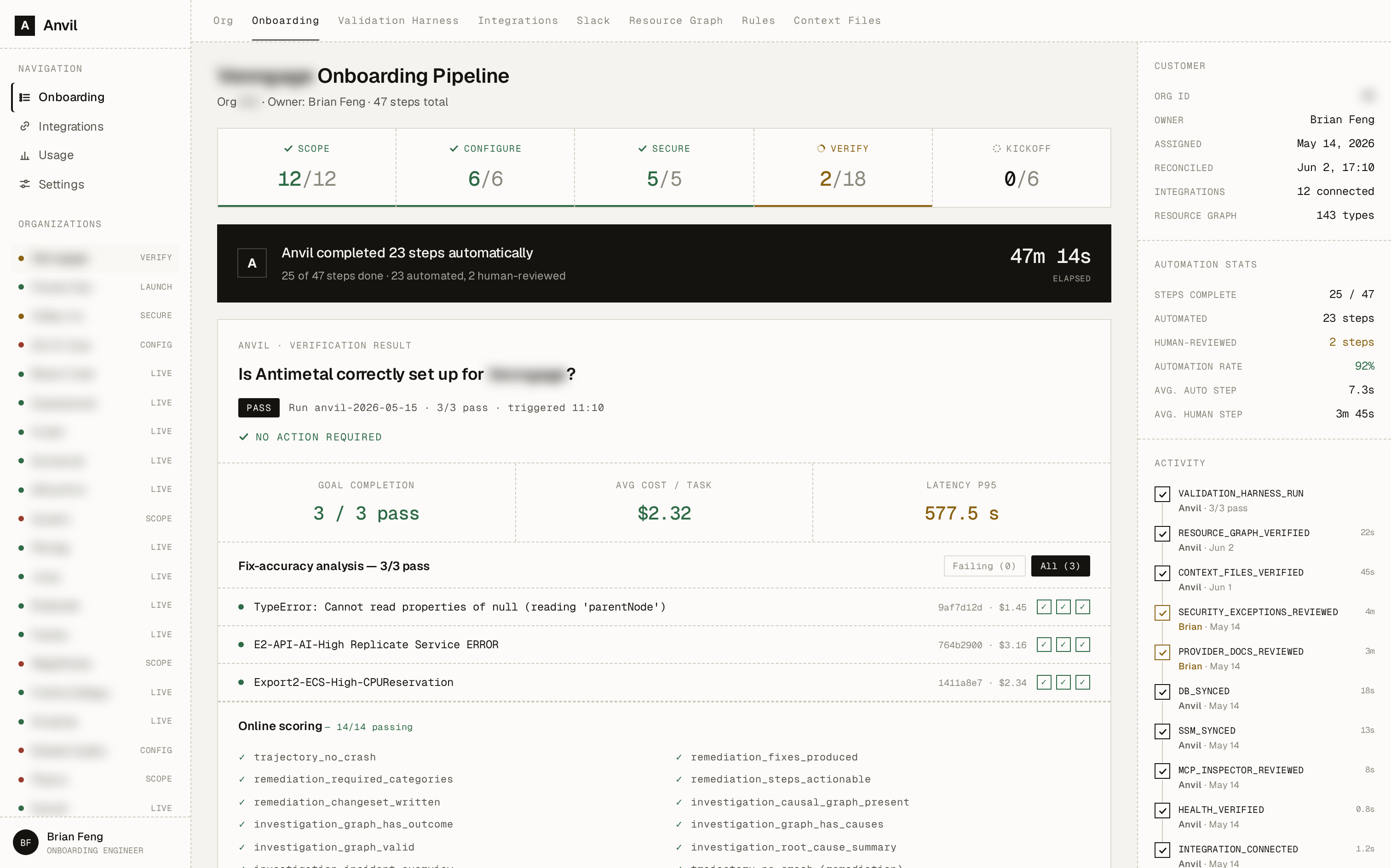
Inside an Anvil onboarding
At Antimetal, we build systems that run production for a team. To operate autonomously inside someone else's environment, we have to understand their setup deeply, which means:
- We need to be code-aware
- We need to be infrastructure-aware
- We need to be business-aware
Code is the part most AI tools already handle. The harder and more valuable work, at least for us, is understanding a customer's infrastructure and business, so that's where Anvil spends most of its effort. The data that Anvil is most focused on during the onboarding process are:
- Qualitative details about a customer's environment, offered directly by them or solicited by us
- Sector- and vertical-specific tech stack properties
- Business operations and process knowledge, shared at the customer's discretion
- User-specific information, sourced through the customer directly and data they offer us via Github and their known org charts
- Software integration and observability vendor access
Consequently, this informs the 5-stage pipeline that Anvil works through:
- Scope: Anvil reviews the customer's business and user-enrichment data and produces a structured profile of who they are and what they need, including the sector- and vertical-specific properties of their tech stack.
- Configure: It then determines how those integrations connect, whether through MCP or REST-based clients, how they're instrumented, what policies apply, and how the customer wants to be notified.
- Secure: Anvil audits every one of the customer's integration surfaces, data sources, and connected accounts, pairing automated checks with a human-driven manual review.
- Verify: Anvil runs the customer-specific eval and validation suites automatically, then a person reviews the results and adds or adjusts tests as needed. This is where the most work happens, since the infrastructure intelligence we sell depends on getting it right.
- Launch: Anvil runs a final set of product fidelity checks and presents a "packaged" experience ready for a human on our team to handoff to the customer.
Changing how new features are developed
Reducing or eliminating the amount of time spent by our team on a task or process is the first thing a good internal tool does. However, the most important thing an internal tool can do is to grow our abilities and make us better at our own craft. Anvil has done both.
The clearest example is how we build new features. To power Anvil's Configure and Verify stages, we've created sandboxed shadow traffic environments to run our product against live customer events. Because of that, any new prototype is tested against real, bounded conditions well before it reaches a design partner.
Our launches have become a lot more reliable as a result, and because this kind of testing no longer takes much effort, we run far more experiments than we used to. A strong and growing product team is built on the back of continuous experimentation, and we've found ourselves accruing valuable product development experience at a many times faster rate since we built Anvil.

What this has meant for us
The most measurable change has been speed. On our most complicated onboardings, the kind that used to eat days of an engineer's time, Anvil has cut the hands-on work by around 80%.
The bigger change is harder to put a number on. Onboarding a customer used to carry a heavy coordination tax. The work was scattered across people and tools, much of it living in a few engineers' heads, with a low bus factor. Now that all of it runs through Anvil, the knowledge sits in one place and stays visible to the whole team.
Building Anvil taught us that forward-deployed engineering does have a real place, but it comes much later than most companies think, after you've automated as much of the work as you can. For a technology company, putting that automation off slows down both your engineers and your customers.